技术人员的设计能力

首
我一直觉得,写代码是一门艺术,一个将世间万物与开发语言建立桥梁的艺术。
既然做为艺术家,那工作自然要有序且优雅。
经常碰到同事会想我咨询问题,比如这个该怎么实现,那个怎么做比较好。承蒙厚爱,尽力解答。
不过在交流的过程中,我发现他们没有“套路”。不是考虑的太少没有设计,就是考虑的太多过度设计。
SHADOW的套路是《分析》=> 《抽象》 =>《效率最大化》。
核心思想是保持不变应对万变。
下面聊聊我对这三步的理解
分析与选型
一天,一个同事问我,客户想平均的分配工单。但是他现在感觉写的特别麻烦,而且容易出问题。那我就问需求是啥,现在是怎么做的。
同事目前在做的是一个工单调派系统,主要的用户是工单处理人员。用户的工作时间为轮班制。
有一天用户提出希望将需要处理的工单平均分配给在线的用户,比如50张工单,5个用户,每人10条。然后工单为实时生成。
原始方案
同事在最初做的时候采用双数组+定时任务的方式,一个数组保存工单,一个数组保存在线用户。
定时任务将数据库内没有分配的工单,在线用户分别存入数组,然后做遍历。
伪代码如下
// 遍历工单
for(Order order: orders) {
// 遍历当前用户
for(User user: users) {
// 小于平均数则分配
if(user.count < avarge) {
// 标记+1
user.count++;
user.currentOrder = order;
}
}
}
这样处理其实在逻辑上没有问题,但是需要维护各个环节的细节,而且代码比较冗余。
一、需要处理“遗留单”的问题,也就是下班了但是活没干完
二、用户是轮班制的,工作的时间不是固定一周5天,可能会是1357,246交错工作日
//周二 平均数10
[{name: "张三", count: 10}, {name: "王五", count: 10}]
//周三 平均数20
[{name: "李四", count: 20}, {name: "王五", count: 20}]
//周四 张三周四平均数为10,根据算法前10个都会分配给张三
[{name: "张三", count: 10}, {name: "王五", count: 20}]
这样需要当天处理数清0,或者自动补齐。一般是当天清0
遗留单比较好处理,定时任务处理增加逻辑判断用户是不是在线,目前也是这么做的
推荐优化方案
经过分析我们抽出几个关键字轮班制,平均分配,在线的用户,实时生成
平均分配
很显然
双数组的数据结构不是很符合要求,维护的复杂度太高,并且不利于扩展。
所以我们需要考虑保证用户拿到的是按照顺序分配的工单,那现实生活中有什么是按照顺序去做的呢?
排队,那是什么在排队呢?用户 因为系统用户数量可控,理论上比业务数据占用的空间更小。所以推荐使用**存储用户信息的队列。
轮班制
轮班制说明用户并不是每天都在工作/登录系统,所以不建议根据处理数量做为逻辑处理
在线的用户
用户必须在线,也就是队列保证存储的是在线用户,这里有两种处理方式
一,登录登出操作队列(主动)
二,队列pop时检查(被动)
实时生成
无法提前通过取余或者平均数的方式分配
结合分析,给出伪代码如下:
// 遍历工单
for(Order order: orders) {
// 获取用户
User user = getUser()
// 有用户就分配,
if(user != null) {
// 分配工单
user.currentOrder = order;
// 把当前用户压入队尾,再排队等待
userQueue.push(user);
}
}
/**
* 获取用户
* 如果队首为空返回null
* 如果用户为非存活用户,继续递归直到返回存活用户或者空
*/
public User getUser() {
User user = userQueue.pop();
if(user == null) {
return null;
}
if(!user.active) {
return getUser()
}
return user;
}
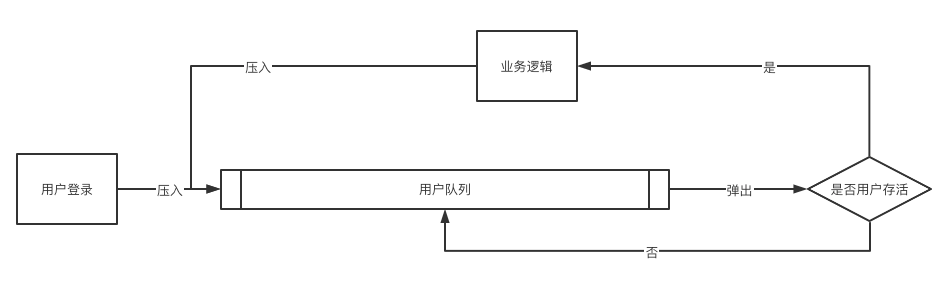
概括的来说
一、通过定时任务,读取数据库的工单循环遍历,每轮循环从活跃用户队列弹出一个用户,如果用户在线,分配工单,然后压入队尾等待分配,如果不在线不做处理
二、用户登录将用户压入队尾等待分配。
三、用户登出将未完成工单修改状态继续等待分配。
通过分析,抽出关键点,再用技术语言做描述,实际简单描述后就是上面的三句话。实际工作中这三句话比一个洋洋洒洒的文档更好用。
抽象与封装
SHADOW所在的另外一个支付类的项目,最近在做重构。在审核代码时发现有一个同事是这么写的,大概的结构如下
@RestController
class Controller{
@Autowired
private Service xxxService;
....service;
@PostMapping(value="/pay/{code}")
public BaseResponse pay(@PathVariable code) {
if(code === Contants.xxx) {
xxxservice.xxx()
} else if(code === Constants.xxx) {
xxxservice.xxx()
}
....
else {
}
}
}
@Service
class Service {
...同样是一堆if-else
}
总之写了一长串的if-else,我觉得
一、太啰嗦了,换成switch也可以嘛(笑)
二、是不是可以优化,这么多if-else很明显不合适,这个类很容易变成超级类,后期会非常难以维护,所以和开发人员沟通了下
其实这个项目向外提供支付能力,商户/商家通过接口调用支付能力,自身不需要对接各种支付平台。所以在交互的参数中需要提供使用的支付渠道,业务类型的参数
通过两个参数可以确定对应的业务实现,比如要不要校验设备,调用什么支付平台等等
实际是多分支多映射的关系
推荐优化方案
经过分析,抽象出一个虚拟实体称之为业务链路,顾名思义就是a+b+n..的组合排列
所以采用业务链路+策略模式
每个业务链路对应一个执行策略,多个业务链路可以共用一个执行策略,保证通用性与扩展性
第一版思路考虑将业务链路与实现类做关联,使用配置文件描述关系,具体结构如下
strategy:
1001/1002/1003: xxxService
2001/2003/3004: xxxService
可以看到都是指向xxxService。所以优化了下配置结构
strategy:
- type:
- 1001/1002/1003
- 2001/2003/3004
executors: xxxService
这样保证业务实现的复用性,考虑到执行service层过于笼统,所以再次优化
strategy:
- type:
- 1002,1003,1004
- 2001,2003,3004
executors: validateDevice,payment,notify
将service再次拆分为细颗粒度的Logic层,例如校验设备(validateDevice),发起支付(payment)等等
概念设计稿
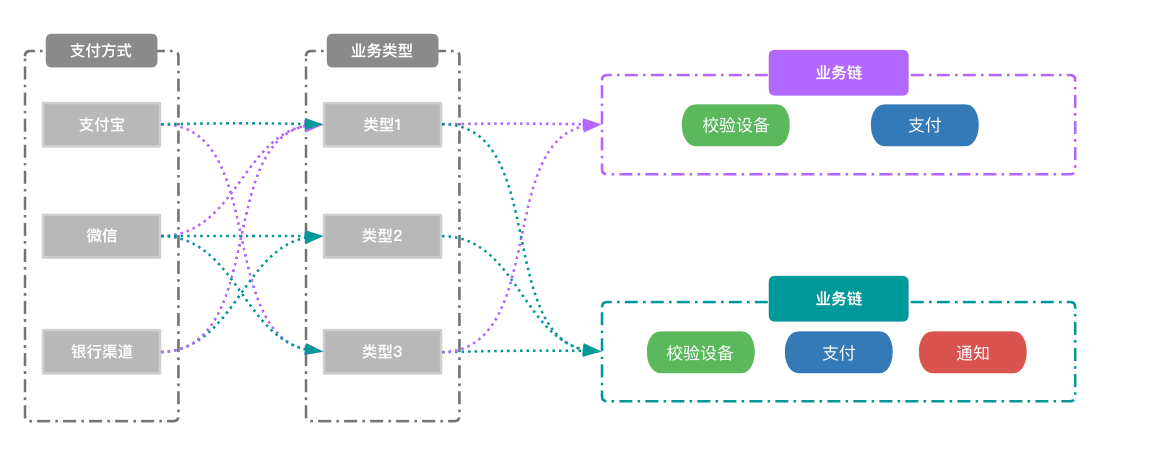
其中包括 系统抽象Logic逻辑接口,LogicChain逻辑链接口, BizStrategy业务策略映射
/**
* 逻辑接口, 逻辑责任链的基础组成
* <p>
* 执行顺序为
* {@link Logic#init()}
* {@link Logic#validate()}
* {@link Logic#run()}
* 执行返回true或者抛出异常,控制事务控制由外层处理
*/
public interface Logic {
// 初始化
default void init() throws Exception {}
// 校验
default boolean validate() throws Exception { return true; }
// 对象校验,可抽象,lambda
default <T> boolean validate(Validate<T> func, T target) throws Exception {
return func.validate(target);
}
// 逻辑实现部分
boolean run() throws Exception;
// 责任链组合调用,默认实现
default boolean doLogic() throws Exception {
init();
if (validate()) {
if (run()) {
return true;
} else {
throw new LogicProcessException("业务逻辑执行错误[" + this.getClass() + "]");
}
} else {
throw new LogicValidateException();
}
}
}
/**
* 逻辑链(责任链)
* <p>
* 将业务拆分为单体责任快,然后组装整合为具体组合业务
*/
public interface LogicChain {
// 逻辑注入
void inject(Logic... logic);
// 执行链路
void doChain() throws Exception;
...
}
/**
* 有序责任链
* <p>
* 按顺序执行逻辑,内部由链表{@link LinkedList}实现
*/
public class SortedLogicChain implements LogicChain {
// 任务链实现
private final List<Logic> chain = new LinkedList<>();
// 逻辑注入
@Override
public void inject(Logic... logic) {
chain.addAll(Arrays.asList(logic));
}
// 执行链路
@Override
public void doChain() throws Exception {
for (Logic logic : chain) {
if (!logic.doLogic()) {
break;
}
}
}
...
}
业务链路配置伪代码如下
/**
* 业务策略组
* <p>
* 描述业务分类,提供策略模式
* 通过策略描述+执行组,提供策略分发/策略工厂的基础支持
*/
@Component
@ConfigurationProperties("app")
public class BizStrategy {
/** 配置映射 */
private List<Strategy> strategies = new ArrayList<>();
public List<Strategy> getStrategies() { return strategies;}
public void setStrategies(List<Strategy> strategies) { this.strategies = strategies;}
/** 策略实体 */
public static class Strategy {
/** 类型 */
private List<String> types = new ArrayList<>();
/** 策略执行器 */
private List<String> executors = new ArrayList<>();
...
}
// 获取执行组
public List<String> getExecutors(String type) throws BizException {
for (Strategy strategy : this.strategies) {
if (strategy.getTypes().contains(type)) {
return strategy.getExecutors();
}
}
throw new BizException("没有找到业务[" + type + "]对应的策略组");
}
// 获取执行组
public List<String> getExecutors(String... types) throws BizException {
return getExecutors(ArrayUtil.join(types, ","));
}
// 获取逻辑链
public LogicChain getLogicChain(String type) throws BizException {
List<String> executors = getExecutors(type);
List<Logic> logicChain = new ArrayList<>(executors.size());
for (String executor : executors) {
// 从Spring上下文中获取实例Bean
logicChain.add(SpringContextHolder.getBean(executor, Logic.class));
}
return DefaultChainFactory.build(logicChain.toArray(new Logic[0]));
}
// 获取逻辑链
public LogicChain getLogicChain(String... types) throws BizException {
return getLogicChain(ArrayUtil.join(types, ","));
}
}
抽象和封装是非常重要的,将实际业务抽象为业务链路+责任链的模式后。增加的业务如果没有特殊需要增加的功能,只需要做对应的配置就好。改动更少,这样就能以不变应对万变
效率最大化
前几天让一个妹子开发一个功能页面,这个功能页面很简单,一个列表,几个按钮。做完觉得我看样式可以调整,于是我打开源码准备帮忙改改配色,做点样式调优。
一打开我就蒙蔽了。一个页面近千行代码,全部写在一个.vue文件里。先不说代码数量
前端最忌讳的就是所有的内容揉在一起,因为相较于后端。前端的调试会非常的麻烦。
这里引用一个vue3的图来说明下

图里显示的是vue2的options-api与vue3-api的区别
在2.0中逻辑是非常分散的,经常需要通过data找methods,或者在methods找data,少的也是几十行上下来回切换
3.0的组合式api的一个优点就是能解决这个问题,每个组合式函数都是内聚的。包含自身完整的数据结构与生命周期,相互独立。这样逻辑更聚焦
虽说项目用的vue2,但是这么写肯定不行,后续维护会非常头大。
问了下妹子为啥这么写,说是觉得做封装太麻烦了....
好吧,先让她做修改,将区域切分干净,然后做对应的封装
其实效率最大化的目的就是后面好干活,能统一做的事不分开两次,三次重复的做
首先让切面页面区块,这个功能大致可以区分为两块
<template>
<div class="container">
<!-- 搜索面板 -->
<div class="search-panel">...</div>
<!-- 数据网格-->
<div class="data-grid">...</div>
</div>
</template>
基本整个项目都需要用到表格,每个页面手动的使用<table><table>实在是有点太繁琐了,所以针对element-table做一点点抽象与封装
<template>
<div class="dynamic-grid-container">
<!-- 表头 -->
<div v-if="title && name" class="header" :class="border ? 'border' : ''">
<!-- 标题 -->
<div class="title">{{ title }}</div>
<slot name="tools" class="tools" />
</div>
<!-- 包装外层 -->
<div v-if="name" class="table-wrapper">
<!-- 表格 -->
<el-table v-bind="$props" v-on="$listeners">
<el-table-column v-if="selection" type="selection" />
<el-table-column v-if="expanded" type="expand">
<template v-slot:default="props">
<slot name="columnProps" v-bind="{ data: props.row }" />
</template>
</el-table-column>
<!-- 不推荐使用index, 需要考虑传入id的属性名 通过item[key]设置每行的key-->
<el-table-column
v-for="(item, index) in filteredColumns"
:key="index"
:filters="item.filters"
:filter-multiple="item.filterMultiple"
:filter-method="item.filterHandler"
v-bind="item"
>
<!-- 提供列插槽机制,绑定行数据. 有需要做扩展 -->
<template v-slot:default="prop">
<slot v-if="item.name" :name="item.name" v-bind="{ data: prop.row, prop: item }" />
<template v-else>{{ prop.row[item.prop] }}</template>
</template>
</el-table-column>
</el-table>
<!-- 附加功能 -->
<div>...</div>
</div>
<Error v-else title="DYNAMIC-GRID-NAME缺失" sub-title="该PROPS必须存在" />
</div>
</template>
<script>
import { Table } from 'element-ui'
import Error from '@/components/Error'
export default {
name: 'DynamicGrid',
components: { Error },
props: {
// 继承element-table属性
...Table.props,
// 可以覆盖element-table的props 或者添加组件 props
// 表格尺寸,默认mini
size: {
type: String,
default: 'mini'
},
...
},
data() {
...
},
computed: {
...
},
methods: {
...
}
}
</script>
<style lang="scss" scoped>
...css style 200+ row
</style>
基本思路就是封装表格组件,继承element-table并扩展自定义组件的属性,实际使用过程中定义对象即可,需要特别优化的通过插槽单独处理
<template>
<div>
<DynamicGrid name="user-list" :columns="columns" :data="data" expanded>
<template v-slot:status="scope">
<el-switch
v-model="scope.data.status"
active-color="#13ce66"
inactive-color="#ff4949"
readonly
/>
</template>
<!-- 列插槽, v-slot:{name}, 名称为具体的columns.name-->
<template v-slot:operator="scope">
<el-button icon="el-icon-search" size="mini" />
<el-button type="primary" icon="el-icon-edit" circle size="mini" />
</template>
<!-- 行扩展操作,需要开启属性expanded -->
<template v-slot:columnProps="props">
<el-form label-position="left" inline>
<el-form-item label="用户编号">
<span>{{ props.data.userno }}</span>
</el-form-item>
<el-form-item label="用户名">
<span>{{ props.data.username }}</span>
</el-form-item>
<el-form-item label="姓名">
<span>{{ props.data.realname }}</span>
</el-form-item>
<el-form-item label="状态">
<el-switch
v-model="props.data.status"
active-color="#13ce66"
inactive-color="#ff4949"
/>
</el-form-item>
<el-button size="mini" type="primary">修改</el-button>
</el-form>
</template>
</DynamicGrid>
</div>
</template>
<script>
import DynamicGrid from '@/components/DynamicGrid/index'
export default {
components: { DynamicGrid },
data() {
return {
columns: [
{ label: '用户编号', type: 'text', prop: 'userno' },
{ label: '登录名', type: 'text', prop: 'username' },
{ label: '姓名', type: 'text', prop: 'realname' },
{
label: '状态',
name: 'status',
prop: 'username',
filters: [{ text: '活动', value: '0' }, { text: '禁用', value: 1 }]
},
{ label: '令牌有效时限', type: 'text', prop: 'expiration' },
{ label: '操作', name: 'operator', width: 200 }
],
data: [
]
}
},
methods: {
...
}
}
</script>
这样表格就基本完成,不需要再一行行的重复写<el-table-column>了,定义表头与数据就好,有需要的再额外扩展
能一次做完就不分两三次重复做
其余部分让妹子继续加油,保持思路正确就行
尾
代码体现技能,注释体现素养
很多时候技术人员觉得实现功能重要
事实上可持续维护才是更重要的
文中的解决方案肯定还有更优解,这里给出的都是当前场景下的、个人认为的较优解
写代码是门艺术活,要写的优雅,干的尽兴,运行的顺利。
这考验的是经验与功底,还有一份技术特有的耐心与坚持